
stouputils.data_science.models.keras_utils.callbacks.learning_rate_finder module#
- class LearningRateFinder(min_lr: float, max_lr: float, steps_per_epoch: int, epochs: int, update_per_epoch: bool = False, update_interval: int = 5)[source]#
Bases:
CallbackCallback to find optimal learning rate by increasing LR during training.
Sources: - Inspired by: WittmannF/LRFinder - Cyclical Learning Rates for Training Neural Networks: https://arxiv.org/abs/1506.01186 (first description of the method)
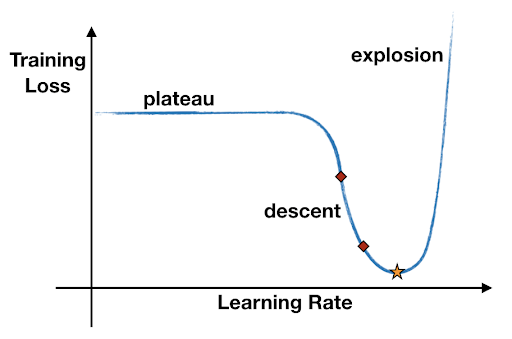
This callback gradually increases the learning rate from a minimum to a maximum value during training, allowing you to identify the optimal learning rate range for your model.
It works by:
Starting with a very small learning rate
Exponentially increasing it after each batch or epoch
Recording the loss at each learning rate
Restoring the model’s initial weights after training
The optimal learning rate is typically found where the loss is decreasing most rapidly before it starts to diverge.
- min_lr: float#
Minimum learning rate.
- max_lr: float#
Maximum learning rate.
- total_updates: int#
Total number of update steps (considering update_interval).
- update_per_epoch: bool#
Whether to update learning rate per epoch instead of per batch.
- update_interval: int#
Number of steps between each lr increase, bigger value means more stable loss.
- lr_mult: float#
Learning rate multiplier.
- learning_rates: list[float]#
List of learning rates.
- losses: list[float]#
List of losses.
- best_lr: float#
Best learning rate.
- best_loss: float#
Best loss.
- model: Model#
Model to apply the learning rate finder to.
- initial_weights: list[Any] | None#
Stores the initial weights of the model.
- on_train_begin(logs: dict[str, Any] | None = None) None[source]#
Set initial learning rate and save initial model weights at the start of training.
- Parameters:
logs (dict | None) – Training logs.
- _update_lr_and_track_metrics(logs: dict[str, Any] | None = None) None[source]#
Update learning rate and track metrics.
- Parameters:
logs (dict | None) – Logs from training
- on_batch_end(batch: int, logs: dict[str, Any] | None = None) None[source]#
Record loss and increase learning rate after each batch if not updating per epoch.
- Parameters:
batch (int) – Current batch index.
logs (dict | None) – Training logs.