
stouputils.collections module#
This module provides utilities for collection manipulation:
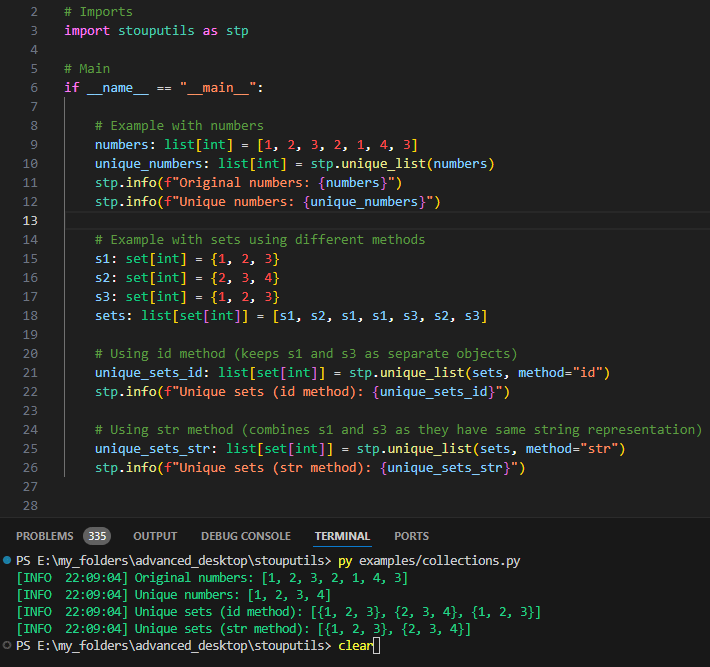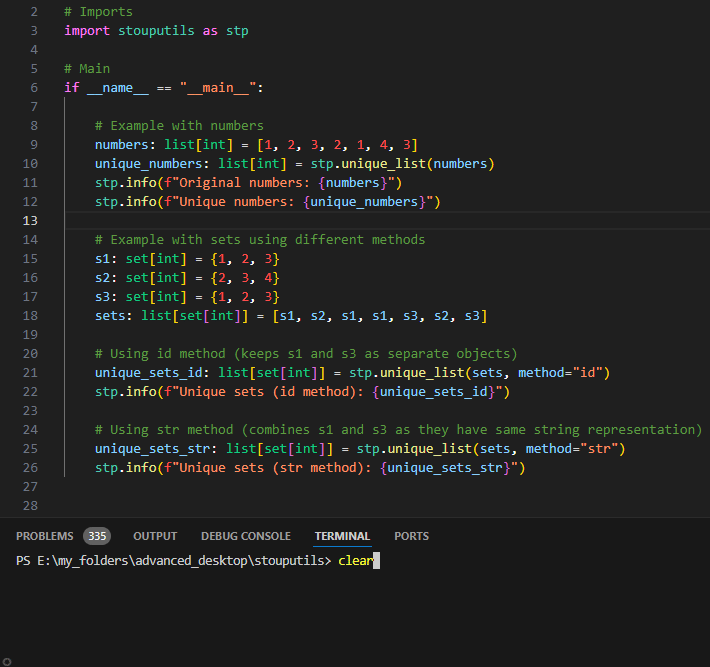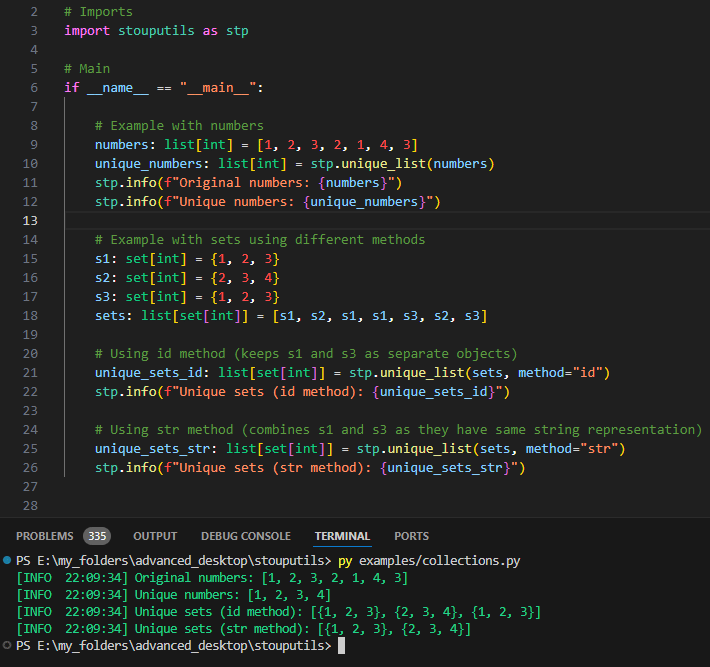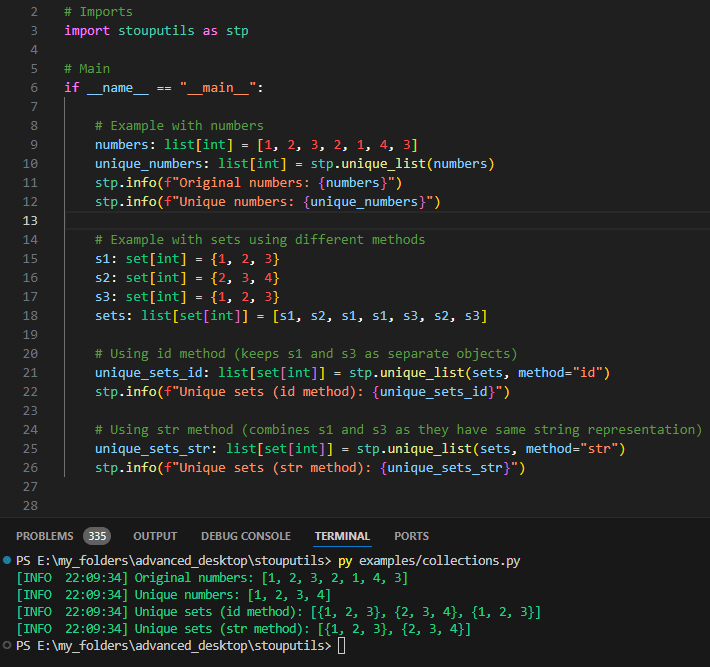
unique_list: Remove duplicates from a list while preserving order using object id, hash or str
array_to_disk: Easily handle large numpy arrays on disk using zarr for efficient storage and access.
- unique_list(
- list_to_clean: list[Any],
- method: Literal['id', 'hash', 'str'] = 'str',
Remove duplicates from the list while keeping the order using ids (default) or hash or str
- Parameters:
list_to_clean (list[Any]) – The list to clean
method (Literal["id", "hash", "str"]) – The method to use to identify duplicates
- Returns:
The cleaned list
- Return type:
list[Any]
Examples
>>> unique_list([1, 2, 3, 2, 1], method="id") [1, 2, 3]
>>> s1 = {1, 2, 3} >>> s2 = {2, 3, 4} >>> s3 = {1, 2, 3} >>> unique_list([s1, s2, s1, s1, s3, s2, s3], method="id") [{1, 2, 3}, {2, 3, 4}, {1, 2, 3}]
>>> s1 = {1, 2, 3} >>> s2 = {2, 3, 4} >>> s3 = {1, 2, 3} >>> unique_list([s1, s2, s1, s1, s3, s2, s3], method="str") [{1, 2, 3}, {2, 3, 4}]
- array_to_disk(
- data: ndarray[tuple[int, ...], dtype[Any]] | Array,
- delete_input: bool = True,
- more_data: ndarray[tuple[int, ...], dtype[Any]] | Array | None = None,
Easily handle large numpy arrays on disk using zarr for efficient storage and access.
Zarr provides a simpler and more efficient alternative to np.memmap with better compression and chunking capabilities.
- Parameters:
data (NDArray | zarr.Array) – The data to save/load as a zarr array
delete_input (bool) – Whether to delete the input data after creating the zarr array
more_data (NDArray | zarr.Array | None) – Additional data to append to the zarr array
- Returns:
The zarr array, the directory path, and the total size in bytes
- Return type:
tuple[zarr.Array, str, int]
Examples
>>> data = np.random.rand(1000, 1000) >>> zarr_array = array_to_disk(data)[0] >>> zarr_array.shape (1000, 1000)
>>> more_data = np.random.rand(500, 1000) >>> longer_array, dir_path, total_size = array_to_disk(zarr_array, more_data=more_data)