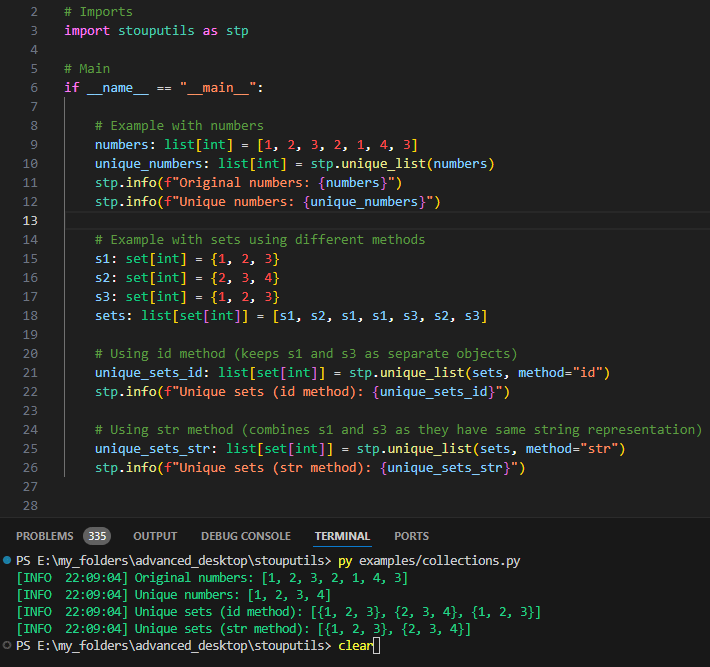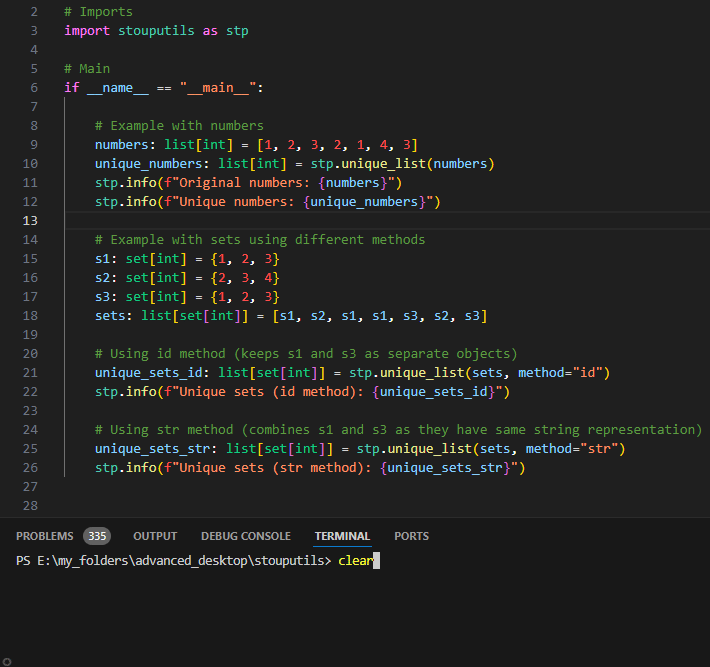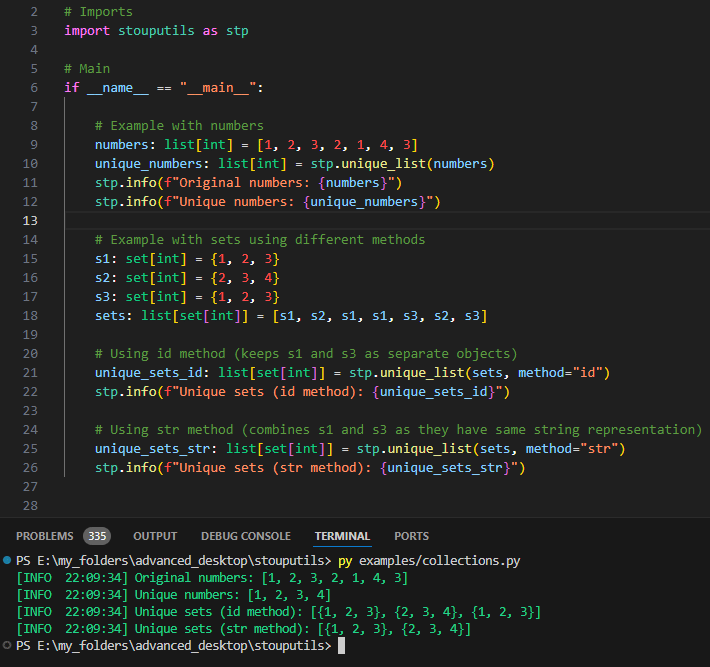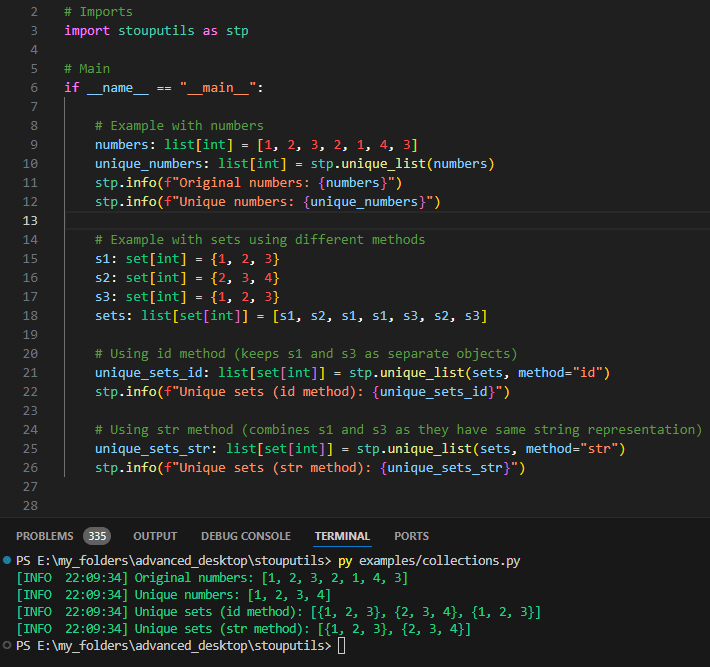
stouputils.collections package#
This module provides utilities for collection manipulation:
unique_list()- Remove duplicates from a list while preserving order using object id, hash or strat_least_n()- Check if at least n elements in an iterable satisfy a given predicatesort_dict_keys()- Sort dictionary keys using a given order list (ascending or descending)affine_permutation_generator()- Generate a memory-efficient pseudo-random permutation of[0, n)feistel_permutation_generator()- Generate a memory-efficient pseudo-random permutation of[0, n)using a Feistel networkupsert_in_dataframe()- Insert or update a row in a Polars DataFrame based on primary keys